Reprinted with permission from "AI at Work", PC AI Magazine (www.pcai.com),
March/April 2001.
Practical Application of Prolog
to eBusiness:
A Racing Case Study
|
|
AI Product Exercised
Product: Amzi! Prolog Logic Server
Vendor: Amzi! Inc.
www. amzi.com
|
Introduction
 A number
of emerging trends in eBusiness can benefit by departing from procedural languages.
Data interchange with disparate systems and the increased sophistication and
dependency on codifying business rules are just two areas presenting business
challenges that the Prolog language is well suited to address.
A number
of emerging trends in eBusiness can benefit by departing from procedural languages.
Data interchange with disparate systems and the increased sophistication and
dependency on codifying business rules are just two areas presenting business
challenges that the Prolog language is well suited to address.
To illustrate the possibilities, lets see
how Youbet.com has applied Prolog in the
advancement of its eBusiness strategy. Along
the way, we’ll also review key lessons and
considerations when applying Prolog to realworld
problems.
Data Interchange With Legacy Systems
The strength of a typical eBusiness
resides in its ability to connect a variety of
business systems directly to the end user —
usually requiring a large amount of data
interchange. Typically, proprietary vendor
record types are converted to a more useful
form, perhaps XML. One challenge here is
the time required to establish, test and
deploy the “glue” software required to interface
the systems. Frequent vendor upgrades
or the vendor’s own XML initiatives can create
an ongoing maintenance burden for the
development team.
Codifying Business Rules
Analytics is often described as the next
revolution in internet technology. In short,
companies analyze their customer behavior
and develop business rules to maximize revenue
growth, loyalty and customer satisfaction.
From the proverbial business rule —
“check credit limit” — to more sophisticated
rules — “show customer related books of
interest” — business rules are constantly
changing and growing increasingly complex.
What these types of problems have in
common is they are both difficult to develop
and maintain with traditional programming
languages. They are all ideal applications for
Prolog. In fact, these applications are so
suited to representation in Prolog that they
seem too simple.
The Problem Domain — Youbet.com
Youbet.com provides a real-time racing
and handicapping service for the established
horse racing customer. The service provides
live audio/video, real-time information feeds
and information products, deriving its revenue from subscription fees, information
product sales, and where legal, live wagering.
It provides access to over 60 tracks around
the country, as well as Australia and Canada.
The service is available on the Internet
through a web browser or a standalone webenabled
CD based application.
Our challenge is to satisfy the needs of
the racing enthusiast. Whether they be an
owner, an established handicapper or a
weekend player, they need timely and germane
information about the races they are
interested in. There is a wealth of information
available, including: live odds, late
changes, audio/video, past performances, tip
sheets and live commentary from the track.
Our business depends on our ability to integrate
all this data and to combine it into an
intelligent presentation for the user.
The Youbet Architecture
Youbet uses an N-tier architecture to
connect web browsers through a session layer
to application servers, vendor systems and
databases. Communication between servers
is typically done through messaging. This
allows us to easily integrate the variety of
application servers, vendor systems and databases
that our service depends on.
Vendor interchange, and codification of
business rules are all implemented through
messaging middleware in the application
tier. A Java based application server with an
integrated Prolog rule base performs these
functions.
The process of interfacing a Prolog rulebase with Java is very straightforward
using a Prolog implementation such as Amzi! Prolog + Logic Server. Once the
amzi.ls package is imported into a Java application, you can consult Prolog
files. You can also extend or optimize Prolog by mapping Java methods to extended
predicates, which are called from the Prolog code.
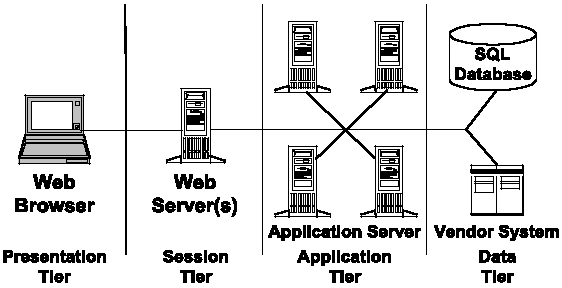
Figure 1: N-Tier Architecture
The Racetrack Application
|
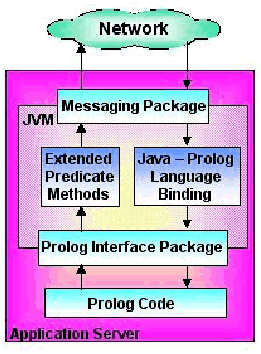
Figure 2: Application Server Architecture
|
Here is one scenario for this application server that involves data interchange
and business rules:
Receive live messages from a racetrack. If the message contains race
results, update content on a web server[1].
Despite the simplicity of this example, the same techniques can be employed
to provide a wide range of compelling user features.
The Implementation
The scenario above is implemented as
follows:
- An outside server sends a message containing live data from the racetrack.
- The Java server receives the message and calls a method handler.
- The foreign message is converted into a crude XML representation.
- The XML is translated to a vendor specific XML format.
- The message is processed according to business rules for the application
domain. For example: If this is an odds message, store the XML on the web
server.
Program Organization
While program organization is always
important, it is critical in a hybrid application
(i.e. Java and Prolog). Developers seem
to have difficulty thinking procedurally and
declaratively at the same time. They must be
able to work primarily in one language at a
time or productivity and quality suffers. In
this system, steps 3, 4 & 5 are performed in
Prolog.
A good design allows the Prolog code
to be tested directly in the Prolog interpreter
(listener), in a hybrid test harness and in the
final application. This requires a test framework
and the ability to pump test messages
from the listener, test predicates, data files
and the network.
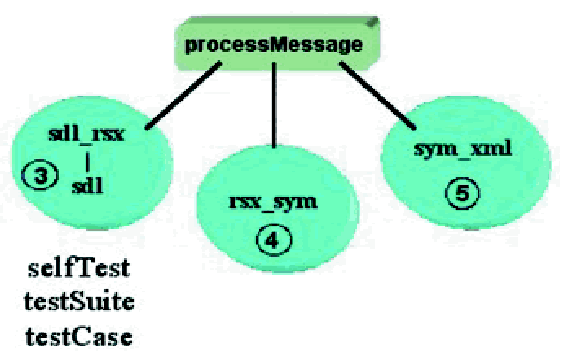
Figure 3: Program Structure
Figure 3 shows the relationship of key
predicates – the lines representing dependencies
between predicates. The ovals represent
predicates that are stored in the same
file. The predicates responsible for steps 3, 4
& 5 of the scenario are also indicated.
The main processing is performed by
the following predicates:
- Main entry point from Java unifies an inbound message with side effects
such as modifying the database or sending other messages (processMessage/1).
- Unify a message in the vendor format (SDL) with its equivalent expressed
as symbolic XML (sdl_rsx/2).
- The DCG representation of the SDL grammar, unifies a difference list with
a parse tree (sdl/3).
- Unify raw symbolic XML with the normalized Document Type Definitions (DTDs)
compliant XML (rsx_sym/2).
- Unify any symbolic representation of XMLwith the actual XML (text sym_xml/2).
The remaining 3 predicates implement
a very flexible test harness. They are present
in every file. If your Prolog implementation
supports name spaces, this is very straightforward.
- Unify with testSuite(pattern) for the current file and selfTest
for every file it depends on, where pattern describes a subset of test cases
(self- Test/0).
- Unify a message in the vendor format (SDL) with all testCases that are described
by pattern (testSuite/1).
- A rule describing a specific test case and identified by a unique term.
A set of test cases is constructed for every predicate in the file. The test
cases are expanded over time to form a regression test suite (testCase/1).
These predicates allow the developer to
build a solid testable rule-base without having
to leave the Prolog environment. The
same test cases can be executed in a hybrid
test harness and the final application. A
comprehensive regression test can be performed
at any time.
Parsing
In steps 3 and 4, the central problem is
parsing a foreign grammar. This is a common
class of problems at Youbet.com since
we have to interface with a number of different
data sources. Before settling on Prolog,
we explored several other approaches.
The traditional approach — Implement a state machine based parser
(perhaps using tools such as Lex and Yacc).
The OOP approach — Implement a parser based on dissecting the
grammar into a class hierarchy.
The AI approach – Implement a Baucus Normal Format (BNF) style
grammar using Prolog.
First the system converts a vendor
message (character list) to a parse tree
(Sdl_rsx). The vendor grammar is represented
by a set of Definite Clause Grammar
(DCG) rules that converts the vendor
grammar into a parse tree. By structuring
the parse tree as follows, the conversion to
XML is trivial:
node ==> <node name>*, attributeList, nodeList | <text>
attributeList ==> [attribute, …]
nodeList ==> [node, …]
attribute ==> <attribute name>*, <attribute value>
* Expressed as a functor
For example, the XML:
<odds track=’AQUEDUCT’ race=’3’ type=’WIN’>
<entry horse=’1’ value=’3-2’/>
<entry horse=’2’ value=’5-1’/>
</odds>
is equivalent to the following Prolog structure.
odds([track(‘AQUEDUCT’),race(3),type(‘WIN’)],[
entry([horse(1),value(‘3-2’)],[]),
entry([horse(1),value(‘3-2’)],[])
])
This simplified structure can be easily
extended to support the broader XML
specification.
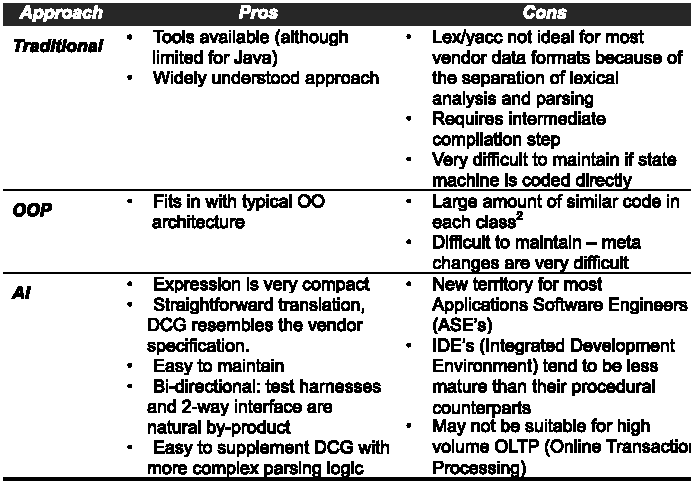
Table 1: Comparison of Parsing Techniques
Message Translation
The parser is most efficent if it is implemented
as a single-pass parser with minimum
backtracking. However, the resultant
XML may not be ideal for the final stage of
processing. The vendor data may be organized
in a non-intuitive way or may utilize
keys or abbreviations that need to be
resolved. Or the XML may not identify
records of a specific type in a uniform way.
Even though other approaches were
explored, expressing the translation logic in
Prolog was ideal since complex rules can be
easily expressed, enhanced and maintained.
The ability to add powerful heuristics is
probably one of the greatest benefits of this
approach since data may contain missing or
inaccurate data can be corrected over time as
patterns are identified.
The data is transformed by developing
a set of rules (rsx_sym) to describe these
abnormalities. Since the XML is already represented
as a Prolog structure, symbolic
manipulation converts this structure to a
format compatible with a standard or vendor
neutral DTD. If you plan to resolve
keys or abbreviations, it is useful to use a
Prolog implementation (such as Amzi!) that
interfaces with SQL databases.
Representing Business Rules
In the application server, business rules
effect change by sending messages to other
systems or by directly acting on the database.
In this case, sending a message to a server
that writes files to a web server. Complex
rules that depend on multiple event conditions
and/or database state changes can be
easily expressed. This higher order processing
can take advantage of the full range of Prolog
constructs and is tailored to the problem
domain. The effects of the rule can be implemented
as extended predicates in Java.
Another example of a business rule use
is in the categorization of news feeds used to
deliver relevant, value-added content — personalizing
the user experience. The rule here
is:
Categorize articles by related players and teams, then deliver these
articles to users who are interested in these players and teams.
Sports articles are received as messages
from news wire services which are converted
into XML as described earlier. At the completion
of step 4, the article is in a uniform
symbolic representation. Individual words in
the article are tokenized and represented as
atoms. The article is then unified against a
set of rules that look for common references
to specific players and teams. Prolog facts
describing players and teams are stored in
the SQL database so they are accessible
throughout the system and easily maintained.
As a final step, the articles are stored
and cross referenced in the database.
Just as in message translation, a major
benefit of the Prolog approach is the ability
to add new heuristics as the application
evolves. A natural progression here would be:
- Recognize only full player names and team names.
- Add the ability to recognize common nicknames and abbreviations.
- Recognize common misspellings, player trades and other complex relationships.
Once the problem domain is better
understood, consider implementing a metagrammar
and interpreter/compiler for rule
expression. This will make it substantially
easier for business analysts and ASEs to
maintain the rule base. Meta grammars are
easily implemented in Prolog.
Users can demo the product by going to http://racing.youbet.com.
You need to become a no obligation trial member to use the product.
Conclusion
It’s hard to imagine a successful eBusiness
that does not have a demand for data
interchange, or business rules. The nature of
these problems presents opportunities for a
Prolog rule-base embedded within a larger
application architecture.
Youbet.com has applied AI technology
and a common architecture to develop an
approach that ties Prolog and messaging
technology together producing a powerful
problem solving tool in the application tier.
This tool establishes a solid foundation on
which the business rules essential to the success
of our customer retention strategies are
built. Incorporating new rules is easy without
requiring significant re-work. Futhermore,
with the correct meta-grammars we believe
that the maintenance of many business rules
can be moved to less technical staff. To date,
we use Prolog to integrate the data from four
different vendors into our eBusiness presence
and many additional applications and
enhancements are being considered.
Using Prolog in a mixed language, distributed
environment has also posed special
challenges. Here are some issues to consider
before using this approach:
- Problem type – Is the problem suited to a declarative language? Do
performance constraints require predictably fast response?
- Skill set – Are the application software engineers ready to think declaratively?
- Tool selection – Does the Prolog implementation provide a solid IDE,
interface with procedural languages and RDBMS?
- Developer productivity – How will the code be tested during and after
development? Will developers be required to task switch between languages?
Will there be a meta-language for describing business rules?
Douglas Tung, C.T.O. and Chief Architect of Youbet.com, an online interactive
horse racing experience can be reached at [email protected]. The Youbet web site
is www.youbet.com.
[1] For simplification, this example has been modified from practice.
[2] For one modest grammar, the parser consisted of over 100 code files, some
representing trivial language elements.