The problem with business rules is they don't all look alike. The rules for one segment of a business refer to different types of things than another, and express different types of relationships. They thus require different points of integration with other business software. Further, the way the rules are applied, or reasoned over, varies based on business area, so the reasoning engines that use the rules are different. Finally, if it is desired to make the entering and maintaining of the rules accessible to the business people who know the rules, then the development environment for the rules must reflect the business practices of those people.
Many relatively simple business areas can use standard database tables for representing the rules, and the reasoning engine can be a simple table look-up program. More complex and interrelated rules require a more sophisticated approach.
This white paper describes an approach to an application-specific rule language, reasoning engine and development environment. The application is customer support, but more specifically, customer support where the rules have access to technical details derived directly from the customer's machine and/or databases with relevant information.
As such, the data and rules need the expressiveness required to encode relationships between complex entities such as directories, system information, and contents of various system or application specific files. Further, the authoring environment must be able to develop and maintain the large dynamic knowledge bases that will evolve in a customer support application.
The application we developed for this environment is called the Amzi! Support Knowledge Tool (SupportKT(TM)). Its design and implementation are the subject of the rest of this article.
These approaches work for certain classes of problem, but they do not work well for situations where the user is required to uncover technical details about his/her machine. A better approach for these situations is a software agent running on the user's machine that can gather information about the machine's configuration and report that information directly to the reasoning engine.
This type of approach is less error-prone than getting information from the user, and allows the automated support system to reason over more complete and accurate data. Further, it is quicker and less irritating for the user. The approach has a side benefit that, if the system can't find an answer, it can escalate the incident to human technical support accompanied by accurate data from the user's machine.
But the agent data from the machine can be richer and more complex than the simple 'fact = value' pairs returned from multiple choice or fill-in-the-blank user questions. And the rules need to be able to work with that richer data representation.
SupportKT uses an object property list data model for information captured from external agents. This is well-suited to gathering file and device information, system properties, and, in a Windows environment, registry entries. The rules include an SQL-like syntax for expressing conditions based on that agent data.
Besides the primary need for a rich data model and rule syntax, an automated support system that uses detailed technical information must address other design issues. These are:
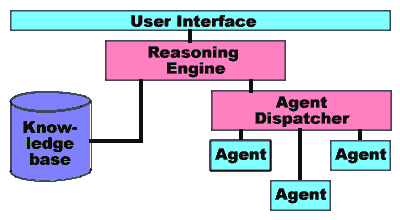
Figure 1
An agent might return a singleton object, such as a 'system' object that has properties for 'processor', 'operating_system', and the like.
The agents respond to queries presented in the same form. For example, a 'file' agent might be queried to find files in a particular directory, or a given file, or a file of a given name greater than a certain size.
Because the agents all implement a standard object interface for SupportKT, it is easy to add additional agents to a system. There is no limit to the type of information they can gather, either from the user's machine or other sources, such as a customer database.
SupportKT addresses this problem by using frame structures to capture information, where many of the slots in the frame provide documentation on the particular rule. The primary frame of SupportKT is called a 'solution'. There are slots such as 'title', 'description', 'owner' and 'version' that are used for documentation and cataloging.
The slots used to solve problems are called 'environment', 'problem' and 'resolution'.
Environments are defined in other SupportKT frames and contain boolean condition statements that determine when the environment exists or not. They are really just like other rules, but are intended to be used to define large areas of commonality between solutions, such as Windows 98 solutions, Sun Solaris solutions, connection problems, printer problems, or whatever makes sense for a particular knowledge base.
For example, a 'solution' that determines a user is running an old version of an application might have a rule like this:
When this solution was being evaluated, the agent that knows how to find 'file' objects would be called with this query, and either return the requested file object and evaluate to true, or evaluate to false if it didn't exist.problem: exists file where [name = "amzi4.dll", path = amzi_bin_directory,
create_date < date(9/9/1998)]
There are a number of other frame structures in a SupportKT knowledge base that support the primary 'solution' frame. These other frames define entities like 'question's which might be asked of the user, 'object_source' which associate agents with objects, and 'derived_fact's which are facts whose values are derived from other facts.
In the example above, the path is compared to 'amzi_bin_directory' which could refer to either a 'question' asked of the user, or a 'derived_fact' that used an agent to get the directory from the registry.
The 'text' objects themselves have multiple slots for translations of the text in various languages. SupportKT will always look for the requested language first, but if a particular 'text' object hasn't been translated, then the first language available is used.
This approach to internationalization is another example of customization for the problem domain. Rather than the normal approach of having translators work on relatively stable files of text, each text object contains its own translations. This allows new solutions to be quickly added to a dynamic knowledge base, and translations to be added when possible.
Where _GAME is a variable.text id: insufficient_memory(_GAME) english: "There isn't enough memory for game" + _GAME
The 'solution' that put out this text might have these slots:
This rule refers to two other SupportKT frames not shown, being a 'table' called 'game_table' which contains games and minimum requirements for running them, and a 'question' called 'requested_game' which asks the user which game he/she is interested in.solution ... problem: _GAME = requested_game and find [_MINMEM = minimum_memory] in game_table
where [name = _GAME] and exists system where [memory > MINMEM] resolution: output = insufficient_memory(_GAME)
Variables provide the means to write very powerful 'derived_facts' that work like subroutines in other languages. For example, one can check if a COM object is configured right by walking the registry and looking for files. A parameterized 'derived_fact' that checks the configuration of any COM object can then be used as a building block for configuration checking solutions that need to check various COM objects as part of the configuration check.
The CSC standard does not, at this point, have the ability to express solutions that reason over objects, as SupportKT does, but it does have the ability to define custom extensions. SupportKT could use these for its objects, but the exported solutions would not be of use to other system unless they could use the richer object rules as well.
On the other hand, the CSC solutions are a subset of what SupportKT can handle, so SupportKT could import solutions developed in other environments and use them directly.
The standards for import/export of customer support solutions is new and evolving, but will eventually provide a way to better preserve investments in knowledge engineering for customer support.
It then prioritizes the solutions and starts to work through them, checking the conditions in the 'problem' slot. The conditions might refer to a question of the user, in which case SupportKT pauses to ask the user, and then continues. The conditions might refer to an object that could be derived from an agent, in which case SupportKT queries the agent and continues. The conditions might refer to a derived fact, in which case the conditions for that derived fact are then considered, which might lead to other questions, etc. etc.
When a solution is found the outputs are assembled and presented to the user. Note that all of the text in SupportKT could be written in HTML and then presented in a broswer to the user.
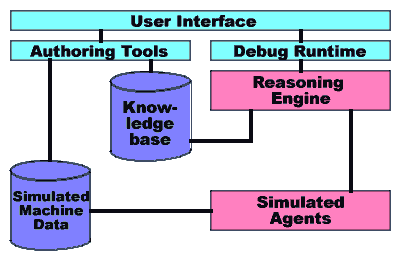
Figure 2
The development environment takes advantage of the frame-based nature of SupportKT knowledge representation. Each of the elements in a knowledge base have their own editor, and tree controls are used to provide a view of the forest through the trees, as shown in Screen Shot 1.
The editor checks the syntax of new solutions, and provides cross-reference information, so that all connections are correctly made.
The development environment debugging runtime tool lets the developer experiment with a knowledge base, as shown in Screen Shot 2. Separate windows come up that contain a full trace of the reasoning, as well as the complete state of knowledge held by the system at any one time. A 'step' button lets the developer step through a knowledge base.
These tools are key for the developer to get a good understanding of exactly how a knowledge base will perform.
Because SupportKT is designed to reason over information gathered from a user's machine, as well as with direct questions to the user, it is necessary to provide data files that simulate the states of various machines. These 'simulation' data files can be used instead of the real agents to test the knowledge base on various machine scenarios.

Figure 3
The API uses XML to pass information to and from SupportKT. Some examples of the API functions supported are:
Java is used for the GUI development and runtime environment and Prolog is used for the underlying knowledge representation and reasoning. Prolog also provides the intelligence behind the editor, providing information to the GUI about the format of various frames and the relationships between them.
The agents that gather information from external sources, such as the user machine, will by necessity be more platform specific. The only common piece is the agent dispatcher that sends agent queries to the appropriate agents. The dispatcher is a C/C++ program, and most agents will most likely be written in C/C++ as well.
The cost, however, is less clear. Aside from normal software fees, the use of a system like SupportKT requires a committment to develop and maintain knowledge bases that solve a significant (useful) percentage of customer problems. The development tools and architecture of SupportKT are designed to make that task as easy as possible, but still it is required to commit human resources to the development and ongoing maintenance.
Further, just as with database, a more talented individual will provide a better organized and more easily maintained knowledge base than a less talented one, so the cost should include all or part of the time of at least one relatively senior individual.
Any organization seeking to automate its customer support needs to fully understand that cost and judge it to be worth the increase in customer satisfaction and savings in normal support costs.
In the final analysis, the value of any rule-based tool is directly related to how cost effective it is for developing and deploying business rules. An application-specific approach, as described here, has the potential for greater cost reduction than a more generic approach, thus making the benefits of automating the rules more widely accesible.